Research
An overview of my research interests and key results.
Auto-generated summary based on recent publications. See InspireHEP for a full list of papers.
The Cosmological Collider
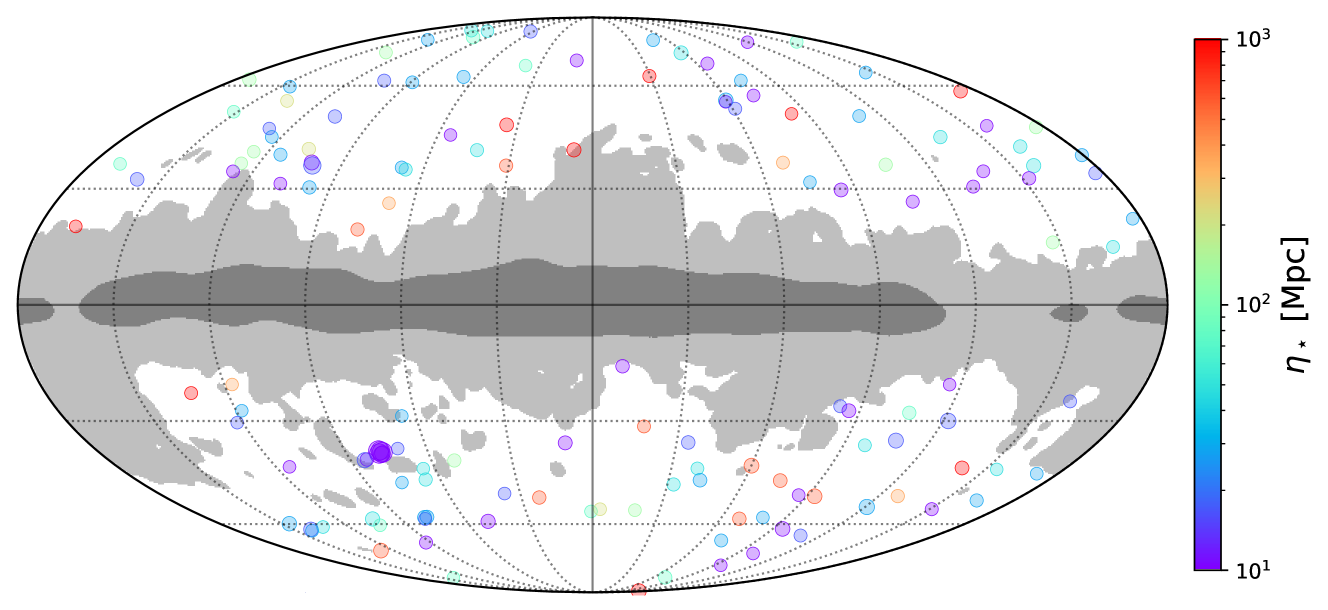
I search for signatures of massive particles produced during cosmic inflation – the “cosmological collider” program. Using both galaxy survey data (BOSS power spectrum and bispectrum) and CMB higher-point functions, I constrain the masses and spins of particles present during inflation, opening a unique observational window into ultra-high-energy particle physics.
Key papers: Philcox, Pimentel & Yang 2026, Cabass, Philcox, Ivanov et al. 2025, Philcox, Kumar & Hill 2025
CMB Higher-Point Functions
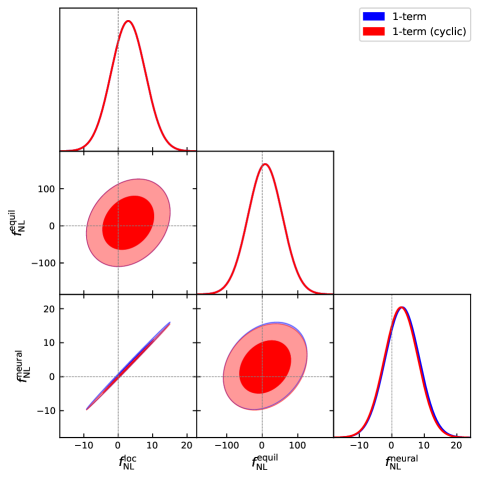
I build efficient optimal estimators for the CMB bispectrum and trispectrum on the full sky, applicable to both scalar and tensor perturbations. I have used these to place the first constraints on the primordial trispectrum from Planck data, to search for tensor and mixed tensor-scalar non-Gaussianity, and to constrain arbitrary primordial bispectrum shapes.
Key papers: Philcox 2026, Philcox 2025, Philcox, Zhong & Sirletti 2025
Galaxy Power Spectrum and Bispectrum Analysis
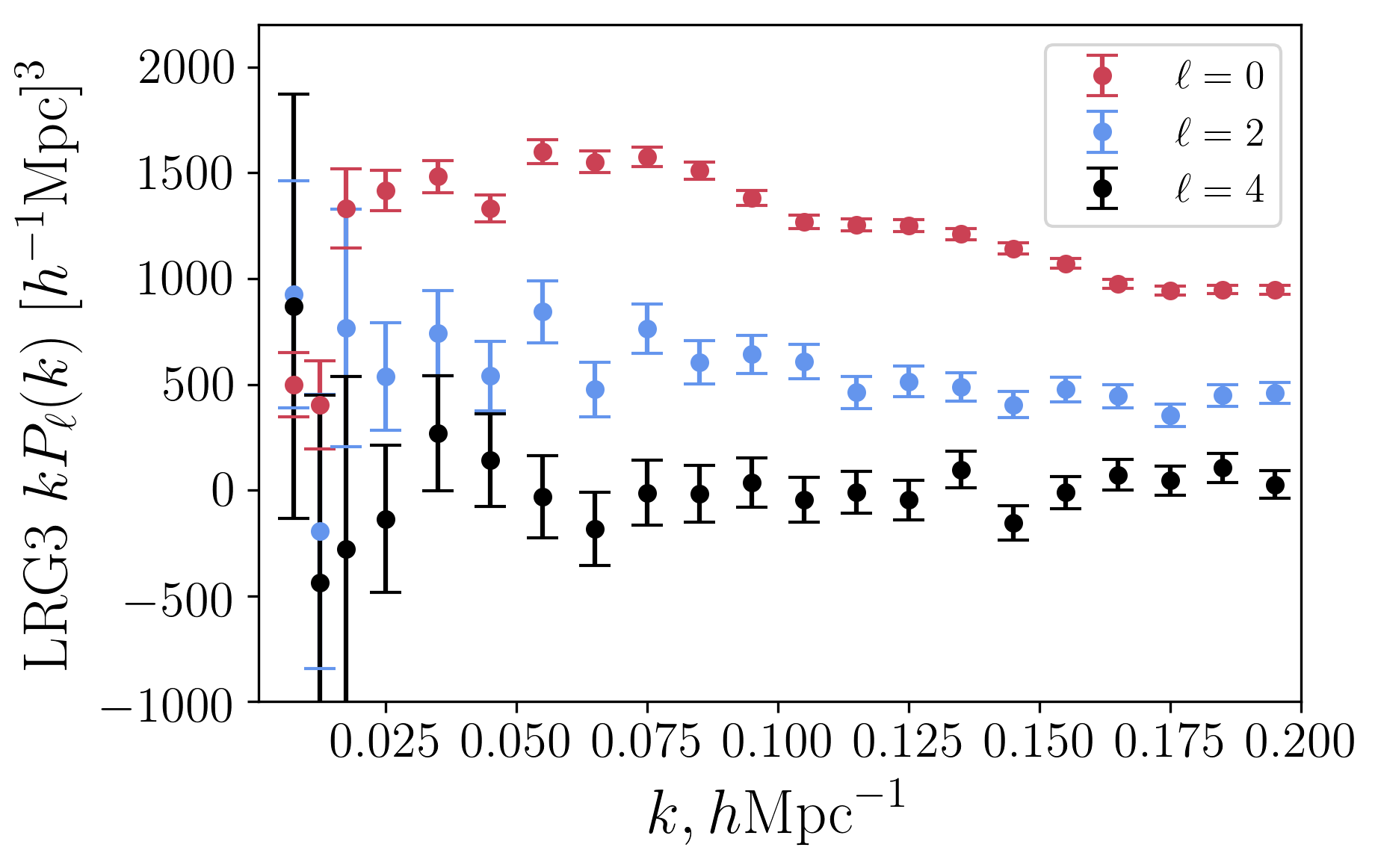
I develop optimal, window-free estimators for measuring galaxy clustering statistics and apply them to state-of-the-art survey data. My recent work includes the first joint power spectrum and bispectrum analyses of BOSS and DESI data using one-loop perturbation theory, yielding precise constraints on cosmological parameters including the Hubble constant, neutrino masses, dark energy, and primordial non-Gaussianity.
Key papers: Ivanov, Sullivan, Chen et al. 2026, Chudaykin, Ivanov & Philcox 2025, Philcox & Floss 2025
Inflation from Galaxy Surveys
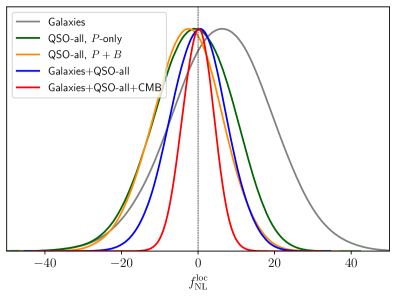
I use the galaxy bispectrum from BOSS and DESI data – analyzed within the framework of the effective field theory of large-scale structure – to constrain models of single-field and multifield inflation. This work provides some of the tightest constraints on primordial non-Gaussianity parameters from galaxy clustering.
Key papers: Cabass, Ivanov, Philcox et al. 2022, Cabass, Ivanov & Philcox 2022, Chudaykin, Ivanov & Philcox 2025
Parity Violation in Cosmology
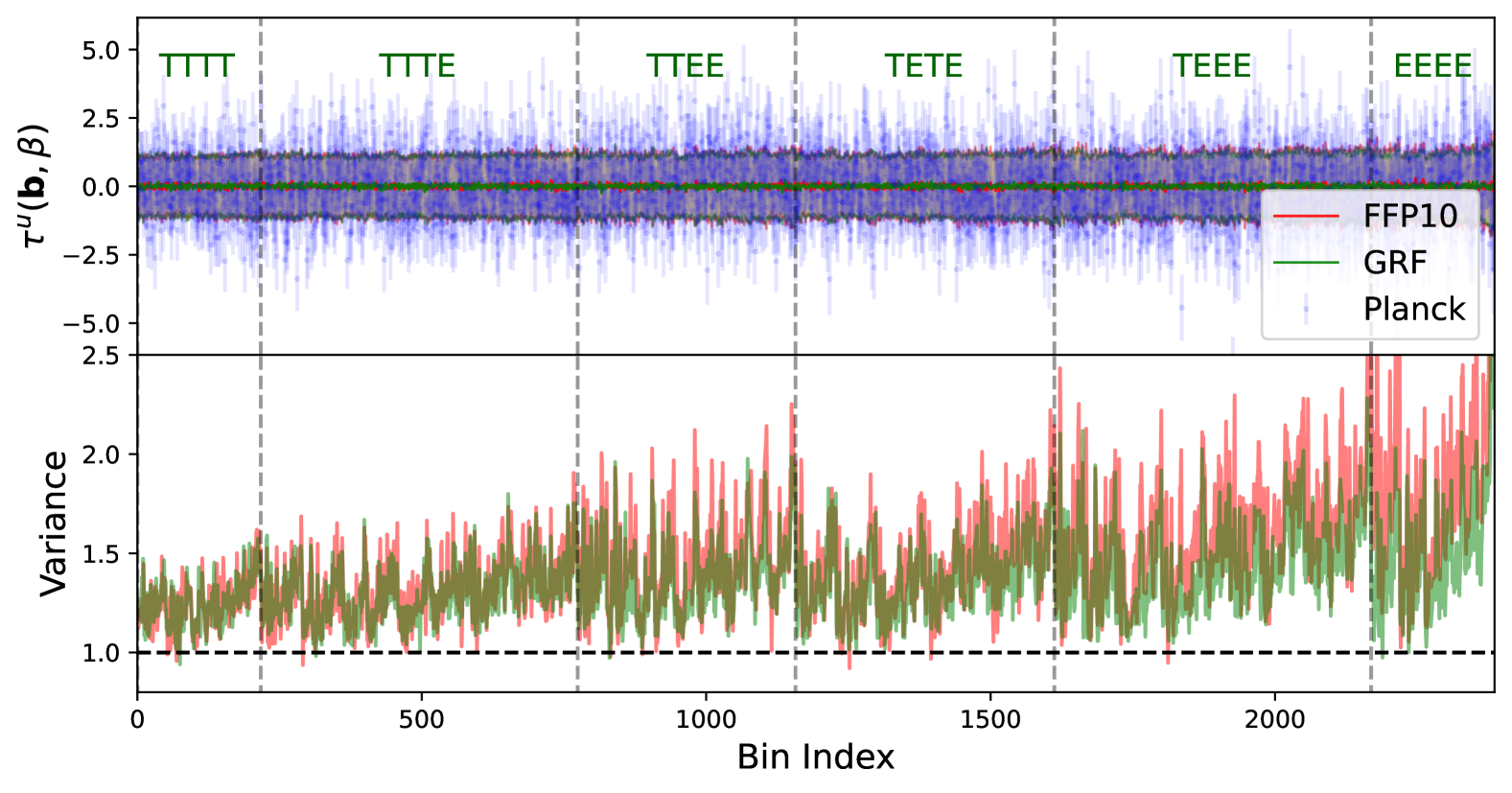
I conduct systematic searches for parity-violating signatures in both galaxy surveys and the CMB. This includes the first measurement of the parity-odd four-point correlation function from BOSS galaxies and tests of parity using CMB temperature and polarization bispectra.
Key papers: Philcox 2022, Philcox 2023, Philcox & Shiraishi 2024
The Hubble Constant and Dark Energy
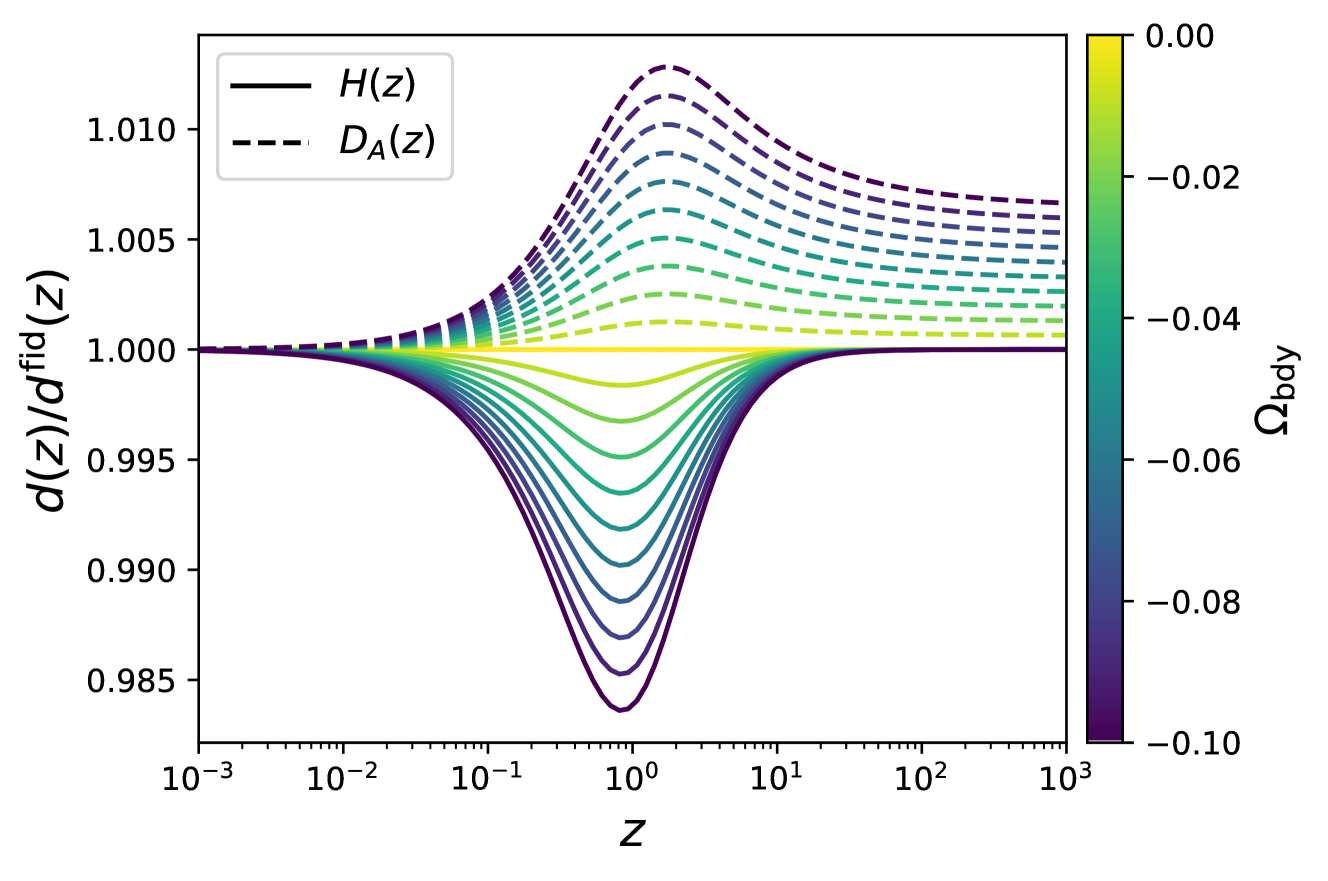
I have pioneered sound-horizon-independent measurements of the Hubble constant using the matter-radiation equality scale from galaxy surveys, CMB lensing, and supernovae. More recently, I have used full-shape galaxy clustering analyses to constrain dark energy models and test beyond-LCDM physics.
Key papers: Philcox et al. 2022, Chen, Ivanov, Philcox & Wenzl 2024, Philcox, Silverstein & Torroba 2025
Simulation-Based Inference
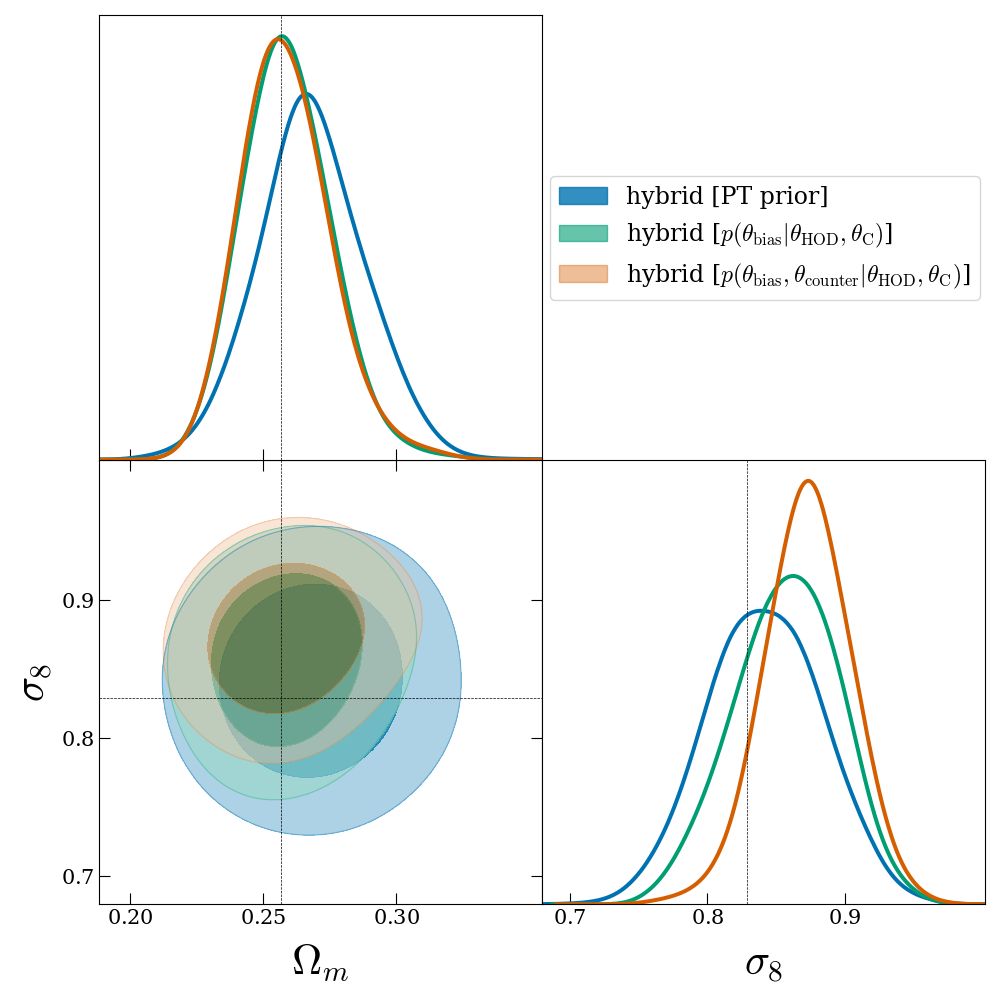
I develop hybrid simulation-based inference methods that combine analytic likelihoods with neural network emulators, enabling more robust cosmological analyses that go beyond traditional summary statistics.
Key papers: Modi & Philcox 2023, Zhang, Modi & Philcox 2026